concepts Link to heading
- cluster: a collection of nodes
- node: part to store data
- index: a collection of similar documents
- type: a category or a partition of indexes
- document: json formated data
- shard/replica: shard of a portion of indexes, whereas replica is a segment of an index.
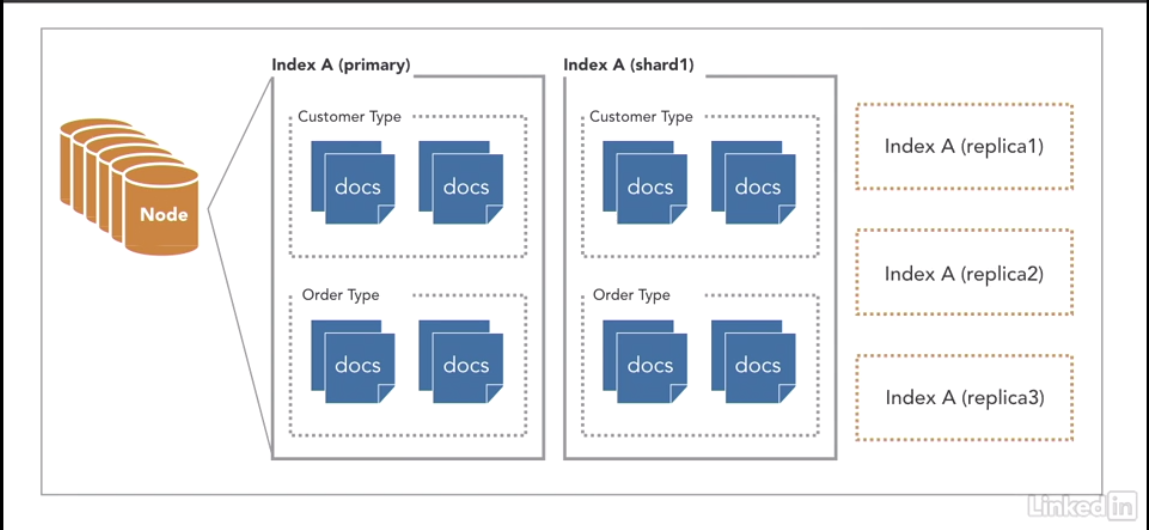
roles of node Link to heading
- master
- data
- ingest: it somewhat like simplified
logstash - ml
by default, it’s dim permission. for different size of cluster, especially medium and large size, we could have dedicated master nodes.
don’t changes roles unless you fully understand what you are doing.
easy CRUD operations Link to heading
<REST verb> <index> <type> <id>
for example: GET _cat/model?v or GET _cat/indices?v
above is getting information out of elasticsearch
or
PUT /sales/order/123
{
"orderID": "123",
"orderAmount": "500"
}
creating documents
it’s best practice to create indices first and then add documents.
or
POST /sales/_update/123
{
"doc": {
"orderID": 1234
}
}
this update a document
scripted update Link to heading
POST /products/_update/123
{
"script": {
"source": "ctx._source.in_stock -= params.quantity",
"params": {
"quantity": 4
}
}
}
ctx is short of context
there are even more complicated scripts
you can insert if conditions diverting operations.
POST /products/_update/123
{
"script": {
"source" : """
if (ctx._source.in_stock == 0) {
ctx.op = 'noop';
}
ctx._source.in_stock--;
"""
}
}
bonus information Link to heading
reading documents – routing Link to heading
how does elaticsearch know which shard to store documents? how are documents found once they have been indexed?
elasticsearch uses routing mechanism to search documents.
shard_num = hash(_routing) % num_primary_shards
as you can see, in the equation there is a parameter called num_primary_shards, and remember we say once shards been created, it cannot be changed. one has to use shrink or split api to reindex to make sure old documents are searchable.
writing doucments – primary term and checkpoints Link to heading
primary terms is a counter for how many times the primary shards has changed (writing operations).
sequence numbers is a counter that being incremented for each write operation. note that primary shards increases the sequence number.
as for checkpoints
each replication group has a global checkpoint and each replica shard has a local checkpoint
global checkpoints is the sequence number that all shards within the replication group has been applied at least up to
local checkpoints is the last write operation that was performed.
checkpoints are essentially sequence numbers
given above information, we could imply when network failing:
when primary shards failed and wants to rejoin, it will just compare with
global checkpointand apply the operations later thanglobal checkpointswhen replica shards failed and wants to rejoin, it will only compare with
local checkpointand only higher number will rejoin.
bulk api Link to heading
when writes many at the same time, we want to use /_bulk API
under /_bulk
in terminal, we do
curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/<index>/<type>/_bulk?pretty --data-binary "@<json_file_name>"; echo
for the file “@<json_file_name>”, there must be an empty line at the end of the file.
in Kibana
POST /_bulk { <action> } { <document> }
data types Link to heading
- core data type: text, numric, boolean, binary
- complex: array, object
- geo: geo_point, geo_shape
- specialized: ip addr, token
meta fields Link to heading
- _index: name of the index
- _id: id
- _source: original json object used when indexing a document
- _field_names
- _routing
- _version
- _meta
mappings Link to heading
for simple use of elasticsearch, mappings are rarely used. but using mappings can control elasticsearch concisely.
or just trust dynamic mapping is good enough.
analyzers Link to heading
once we index a document, elasticsearch will run the whole analyze process. when later we search, we are not searching the document; we are searching the inverted index.
analyzer consists of (sequential order):
- character filters: to manipulate text before tokenization. like taking out some mark up language such as html, defaults are:
- html strip filter
- mapping character filter
- pattern replace
- tokenizer: chop words into term. i.e. do some logic on top of tokens, like lower the case, etc. 3 main categories are:
- word oriented tokenizers
- standard tokenizer (
standard) - letter tokenizer (
letter) - lowercase tokenizer (
lowercase) - whitespace tokenizer (
whitespace) - uax url email tokenizer (
uax_url_email)
- standard tokenizer (
- partial word tokenizers
- N-Gram tokenizer (
ngram): “red wine” -> [re, red, ed, wi, win, wine, in, ine, ne] - edge N-Gram tokenizer (
edge_ngram)
- N-Gram tokenizer (
- structured text tokenizers
- keyword tokenizer (
keyword) - pattern tokenizer (
pattern) - path tokenizer (
path_hierarchy)
- keyword tokenizer (
- word oriented tokenizers
- token filters: get rid of some white spaces, comma, etc
stardardlowercaseuppercasenGramedgeNGramstopword_delimiterstemmerkeyword_markersnowballsynonym
standard analyzer doesn’t contain a character filter
analyzers by default:
simple analyzerstop analyzerlanguage analyzerkeyword analyzerpattern analyzerwhitespace analyzer
customizing analyzers
heirachy: settings -> analysis -> analyzer/filter/......
analyzer can be also created by our own. with in analyzer block, we need to give tokenizer, char_filter, token filter(s)
previously, people remove stop words before analyze. but with the development of search algorithm, we don’t need to remove stop words anymore because search algorithm will handle stop words pretty well.
inverted index : an index data structure storing a mapping from content to index. Link to heading
there are two types of
inverted index, arecord-level inverted indexand aword-level inverted index.
the latter form asked for more processing power and space.
a concrete example
Suppose we want to search the texts “hello everyone, " “this article is based on inverted index, " “which is hashmap like data structure”. If we index by (text, word within the text), the index with location in text is:
hello (1, 1)
everyone (1, 2)
this (2, 1)
article (2, 2)
is (2, 3); (3, 2)
based (2, 4)
on (2, 5)
inverted (2, 6)
index (2, 7)
which (3, 1)
hashmap (3, 3)
like (3, 4)
data (3, 5)
structure (3, 6)
query/search Link to heading
elasticsearch uses query DSL, a query based on JSON
query DSL Link to heading
- Leaf Query: search values in particular field
- Compound Query: contains multiple leaf queries or compound queries themselves
algorithm using behind _score
Link to heading
elasticsearch previously used TF/IDF, but now it uses BM25. in general, they are similar, but there are still slight differences. because similarities in general, we will discuss TF/IDF anyways.
- term frequency
TF: it looks how many times the term appear in a given DOCUMENT. the more it appears, the more important - inverse document frequency
IDF: how often does the term appear in INDEX (all documents). the more it appears, the less important
TF/IDF formula is w(i, j) = tf(i, j) x log(N/df(i)) where
tf(i, j) is number of occurrences of i in j
df(i) is number of documents containing i
N is total number of documents
- a third factor to consider: field length norm
meaning how long the field is. if the term appear in a field with length 50, then it’s more important than the same appearing in a field with length 5000.
query context and filter context Link to heading
- query context will calculate relevance score
- filter context do a boolean evaluation, it’s either a match or not.
term level and full text query Link to heading
term level query doesn’t do analyzing, it searches in inverted index.
full text query search analyzed text fields. meaning it will analyze first.
one condition Link to heading
match all query
GET bank/account/_search
or
GET bank/account/_search
{
"query": {
"match": {
"state": "CA"
}
}
}
remember match with analyze text first
multi conditions Link to heading
GET bank/account/_search
{
"query": {
"bool": {
"must/must_not": [
{"match": {
//match condition 1
}},
{"match": {
//match condition 2
}}
]
}
}
}
this is more like a bool query
bool query usually used for multiple queries
boost Link to heading
key word boost is to boost the document to the front, in another word, making the document higher priority.
boost works with should
example:
GET bank/account/_search
{
"query": {
"bool": {
"should": [
{"match": {"state": "CA"}},
{"match": {"lastname": {"query": "Smith", "boost": 3}}}
]
}
}
}
the above query will boost field lastname, it will affect _score
term-level query Link to heading
term only works with keywords and numeric values, will not work with text field
terms can query multiple input
range will query with gte and lte, searching in that range
example:
GET bank/account/_search
{
"query": {
"range": {
"account_number": {
"gte": 516,
"lte": 851,
"boost": 2
}
}
}
}
joining queries Link to heading
in theory, in elaticsearch, or all key-value pair storage, it’s not like relational db has primary keys and foriegn keys.
the idea ‘join’ is usually completed in application level.
nested inner hits Link to heading
inner hits is a option of nested, will tell insights which hits object are comming from
join_field Link to heading
define parent child relations or define which side this document belongs to, parent or child.
parent and child documents have to be in the same shard. so we have to provide routing id.
has_parent, has_child Link to heading
analysis and tokenization Link to heading
analyze endpoint will analyze the the text, and give the token.
example
GET bank/_analyze
{
"tokenizer": "standard",
"text": "The Moon is Made of Cheese someone say"
}
here tokenizer works like a delimiter
there is also one keyword called analyzer, which will direct es what to do with the field, for example: standard analyzer will lower case all text whereas english analyzer will delete plural form.
analyze data Link to heading
aggregation Link to heading
aggs means aggregation. aggs can be nested into another aggs
very complicated example:
GET bank/account/_search
{
"size": 0,
"aggs": {
"states": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"avg_bal": {
"avg": { "field": "balance" }
},
"gender": {
"terms": { "field": "gender.keyword" }
},
"aggs": {"avg_bal": {"avg": { "field": "balance" }}}
}
}
}
}
stats is very useful as well.
filter aggregation Link to heading
one way doing it is before aggs, using query to filter.
GET bank/account/_search
{
"size": 0,
"query": {
"match": {"state.keyword": "CA"}
},
"aggs": {
"states": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"avg_bal": {
"avg": { "field": "balance" }
},
"gender": {
"terms": { "field": "gender.keyword" }
},
"aggs": {"avg_bal": {"avg": { "field": "balance" }}}
}
}
}
}
another way is using filter keyword
GET bank/account/_search
{
"size": 0,
"query": {
"match": {"state.keyword": "CA"}
},
"aggs": {
"over35": {
"filter": {
"range": {"age": {"gt": 35}}
}
},
"aggs": {"avg_bal": {"avg": {"field": "balance"}}}
}
}
using filter, we can filter in aggreation level (inside aggragation).
metrics aggregation Link to heading
"aggs" : {
"FIELD" : {
"AGG_TYPE" : { "field": "xxxxxx" }
}
}
AGG_TYPE could be
- sum
- avg
- min
- max
- cardinality
- value_count
- amount_stats
bucket aggregation Link to heading
bucket aggregation will create bucket for each unique value according to criteria.
term aggretion
aggregation can be nested in aggregations
the outer layer of aggregation is queried in context of query, and inner aggregation is queried in context of aggregated/filtered context.
global aggregation can be only placed on top level of the query.
nested aggregation can be used doing fancier queries
improve searches Link to heading
proximity Link to heading
using slop, meaning how far allowed of terms (edit) distances (despite terms order)
proximity affects relevances scores
consider must working with should in bool query
fuzziness Link to heading
using levenstien distances behind the scene
operating on term level
fuzziness also introduce transipositions
synonyms Link to heading
use POST /synonyms/_update_by_query to update synonyms, or the documents wouldn’t be re indexed.
highlight Link to heading
we can use highlight to highlight matches.
stemming Link to heading
percentiles and histagram Link to heading
keywords: percentiles, hdr, percentile_ranks, histagram
they are helping to understand the distribution of data inside es.
visualization Link to heading
create visualization first and then use those ‘modules’ to dashboard.