Before anything, amazon always set minimum permissions generally.
region and availability zone Link to heading
- A region is a physical location in the world which combines two or more availability zones.
- zone is one or more discrete data centers each with redundant power networking connectivity housed in
- edge locations are endpoints for AWS which are used for caching content. like cloudflare and other CDN services.
- vpc(virtual private cloud): a networking service which is a logically isolated section of the AWS Cloud where you can launch AWS resources in a virtual network
IAM (identity administrating management) Link to heading
- IAM is universal
root accountis the account created when first setup the aws console, it has the admin access- no users have permission when first created
- new users are assigned Access Key ID & Secret Access Keys when first created
- Access Key ID & Scret Access Keys are used to programaticaly access AWS console, and they only got viewed Once.
- always setup multi factor authentication (MFA) on your root account
- you can create you only password rotation policy and many other policies.
IAM roles Link to heading
aws doesn’t recommend using aws_access_key_id and aws_secret_access_key to use aws command line.
it’s much more secure to use IAM roles
use action–>attach/replace IAM roles to do so.
- roles can be assigned to an EC2 instance after it’s created using both the console & command line
- roles are universal - you can use them in any region
Instance profile is a constainer for IAM roles. When create a role for EC2, the console automatically createa an instance profile and gives it the same name as the role. When launching EC2 instance, you can select a role to associate with the instance.
IAM Policies Link to heading
IAM Policy is a JSON document that defines permissions. It can be identity policy or resource policy. It contains a list of statements.
It won’t be effective until it got attached.
example is the following
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SpecificTable",
"Effect": "Allow",
"Action": [
"dynamodb:BatchGet*",
"dynamodb:Get",
......
],
"Resource":"arn:aws:dynammodb:*:*:table/MyTable"
}
]
}
Sidis human readable id/descriptionsEffectis eitherAlloworDeny. Not explicitly allowed is implicit deny; explicitly deny overwrite all the following deny.Actionmatched based on the contents defined inside.Resourceis the action that go against. In the above example, it is against dynamodb. the Resource has to comply ARN. All ARNs are with following structure:arn:partition:service:region:account_id:resource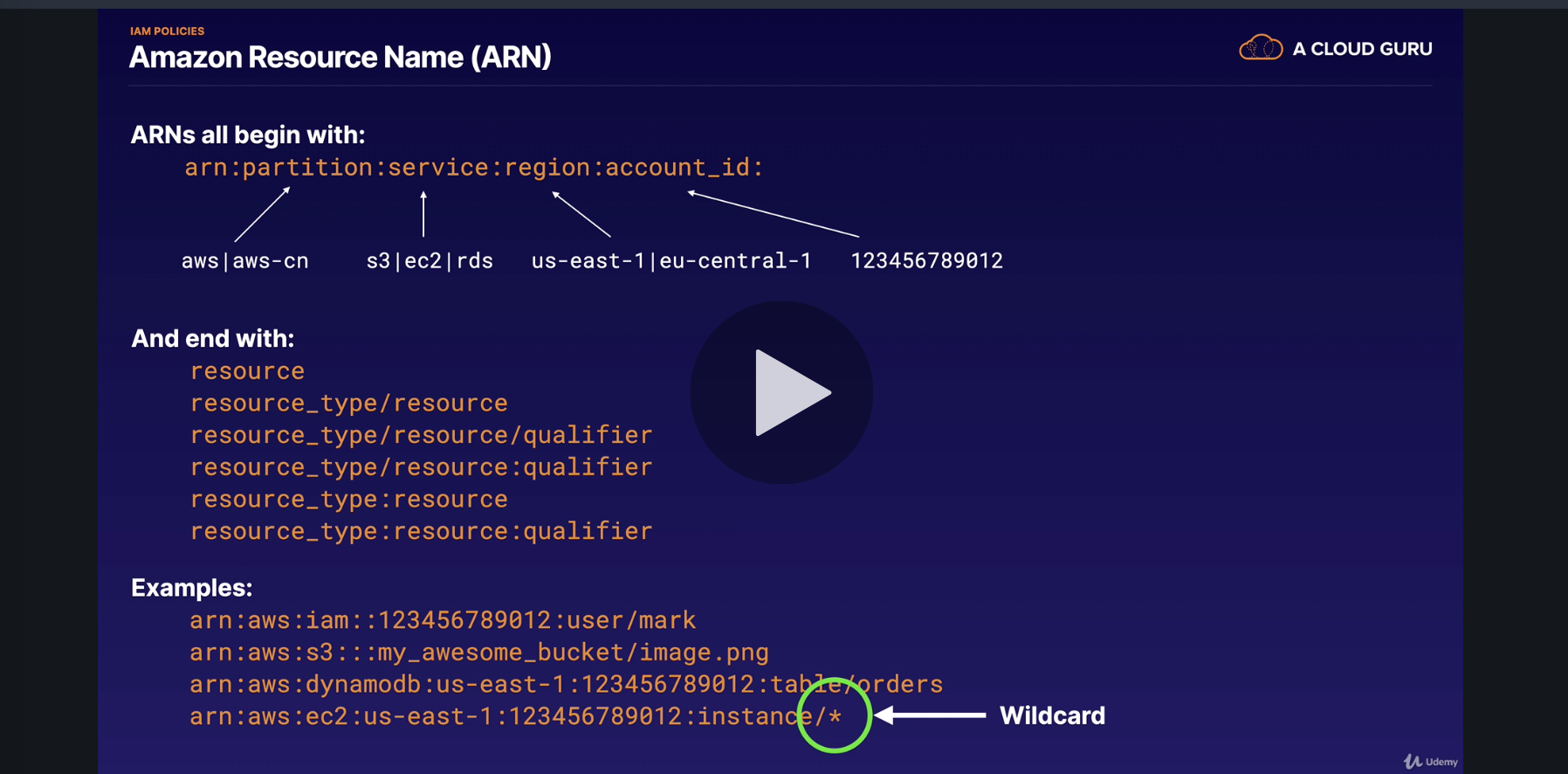
IAM policy joins all other applicable policies. There are AWS managed IAM policy that you could use, however you are always free to create your own IAM policy. It’s used to delegate administration to other users to prevent privilege escalation or unnecessarily broad permissions. You can control the maximum permissions IAM policy can grant.
use cases including
- developer create roles for lambda function
- application owner creates roles for EC2 instances
- admin create ad hoc users.
Resource Access Manager Link to heading
RAM allows resource sharing between accounts. Not all the services can be shared.
Single Sign On (SSO) Link to heading
SSO helps centrally managing access to AWS accounts and business applications.
IAM miscellaneous Link to heading
- power user access allows access to all AWS services except the management of groups and users within IAM
- a policy is a document that provides a formal statement of one or more permissions
How to be alarmed Link to heading
CloudWatch and create an alarm
S3 Link to heading
general overview Link to heading
- S3 is Object-based storage, cannot hold db or os on top it.
- files can be from 0 Bytes to 5TB
- unlimited storage
- files are stored in
Buckets - S3 is a universal namespace, names must be unique globally
- control access to buckets using either a bucket ACL or using Bucket Policies
- successful uploads will generate HTTP 200 status code
- you can turn on MFA to prevent accidental deleting
fundamentals Link to heading
Keyis simply the name of the objectValueis simply the data and is made up of a sequence of bytesVersion IDis important to distinguish versionsMetadataSubresourcesincludes Access Control Lists and Torrent- S3 has Read after Write consistency for PUTS of new objects
- Eventual consistency for overwrite PUTS and DELETES (might need time to propagate)
here is a table to compare
| S3 Standard | S3 Intelligent-Tiering* | S3 Standard-IA | S3 One Zone-IA† | S3 Glacier | S3 Glacier Deep Archive | |
|---|---|---|---|---|---|---|
| Designed for durability | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) |
| Designed for availability | 99.99% | 99.9% | 99.9% | 99.5% | 99.99% | 99.99% |
| Availability SLA | 99.9% | 99% | 99% | 99% | 99.9% | 99.9% |
| Availability Zones | ≥3 | ≥3 | ≥3 | 1 | ≥3 | ≥3 |
| Minimum capacity charge per object | N/A | N/A | 128KB | 128KB | 40KB | 40KB |
| Minimum storage duration charge | N/A | 30 days | 30 days | 30 days | 90 days | 180 days |
| Retrieval fee | N/A | N/A | per GB retrieved | per GB retrieved | per GB retrieved | per GB retrieved |
| First byte latency | milliseconds | milliseconds | milliseconds | milliseconds | select minutes or hours | select hours |
| Storage type | Object | Object | Object | Object | Object | Object |
| Lifecycle transitions | Yes | Yes | Yes | Yes | Yes | Yes |
always refer to AWS FAQ
encryption Link to heading
encrpytion in transit is achieved by SSL/TLS
- server side encryption
- S3 Managed keys - SSE - S3
- From AWS Key Management Service called Managed Keys - SSE - KMS
- Customer Provided Keys - SSE - C
- client side encryption
versioning Link to heading
- versioning stores all versions of an object (including delete, it will be a delete marker)
- it’s a great backup tool
- once enabled, versioning cannot be disabled, only suspended
- it can be integrated with lifecycle rules
- versioning’s MFA delete capability can be used to provide additional layer of security
life cycle rules Link to heading
can find life cycle rules under management
it
- automates moving your objects between the different storage tiers
- can be used in conjuction with versioning, can be applied to current version or previos version
S3 Object Lock and S3 Glaciers Vault Lock Link to heading
S3 Object Lock S3 Object Lock you can use Write Once Read Many policy (WORM policy).
There are two modes that you could choose. Governance Mode or Compliance Mode.
- Governance mode user cannot overwrite or delete object version or alter its lock settings unless he has special permission.
whereas
- Compliance mode user cannot delete or overwrite protected objects even he is a root user. Its retention mode cannot be changed and retention period cannot be shortened.
Retention Retention is a period of time protects an object for a fixed amount of time. After the retention expired, the object version can be overwritten or deleted unless you also place a legal hold on the object version.
Legal Hold A legal hold is like a retention period that prevent people overwrite or delete on an object version. Unlike retention period, people can freely place legal hold if he has
s3:PutObjectLegalHoldpermission.S3 Glacier Vault Lock It allows you easily deploy and enforce Compliance control for individual glacier vault with a vault lock policy. You can specify controls such as WORM and lock policy from future edits. Once locked, the policy can no longer be changed.
S3 Performance Link to heading
S3 Prefix
the strings between bucket name and object name. for example:
mybucketname/myfolder/subfolder1/object.jpgprefix is/myfoldre/subfolder1/Number of Requests
Currently AWS can do 5500 GET/HEAD and 3500 PUT/COPY/POST/DELETE per second per prefix. So if you want to increase speed of reads, you can spread to different prefixes. for example, if we have 2 prefix, we could achieve 11000 reads per second.
KMS Limits
If you are using SSE-KMS to encrypt your object, uploading and downloading will count towards the quota. It’s either 5500/10000/30000 depends on regions. Currently you cannot increase the quota.
Multi upload and byte range fetches
Use multi uploads to upload file over 100mb and must use it when file’s over 5GB. User byte range fetches to increase performance when downloading files to S3.
S3 Select & Glacier Select Link to heading
S3 Select is used to retrieve only a subset of data using SQL query, it saves money on data speed and cost. Glacier Select is a similar stuff.
DataSync Link to heading
DataSync is used to transfer large amount of data from on-promise data center to AWS. DataSync can be used with NFS- and SMB- compatible file system. Replication can be done hourly, daily or weekly.
After installing DataSync Agent in on-promise data center, it can start replication. It can be used to replicate from EFS to EFS.
S3 miscellaneous Link to heading
- Until 2018 there was a hard limit on S3 puts of 100 PUTs per second. To achieve this care needed to be taken with the structure of the name Key to ensure parallel processing. As of July 2018 the limit was raised to 3500 and the need for the Key design was basically eliminated. Disk IOPS is not the issue with the problem. The account limit is not the issue with the problem.
- OneZone-IA is only stored in one Zone. While it has the same Durability, it may be less Available than normal S3 or S3-IA.
- S3 has multipart upload API to deal with large file uploading
- Virtual style puts your bucket name 1st, s3 2nd, and the region 3rd. Path style puts s3 1st and your bucket as a sub domain. Legacy Global endpoint has no region. S3 static hosting can be your own domain or your bucket name 1st, s3-website 2nd, followed by the region. AWS are in the process of phasing out Path style, and support for Legacy Global Endpoint format is limited and discouraged. However it is still useful to be able to recognize them should they show up in logs. https://docs.aws.amazon.com/AmazonS3/latest/dev/VirtualHosting.html
- 100 buckets per account by default
aws organizations Link to heading
we can enable/disable aws services using Service Control Policies (SCP) either on OU or on individual accounts
want to perform as another role? three ways sharing S3 buckets across accounts
how to grant cross acccount access
- [programmatic access only] using bucket policies & IAM (applies across the entire bucket)
- [programmatic access only] using bucket ACLs & IAM (individual objects)
- cross account IAM roles. this is both console access and programmatic access
cross region replication Link to heading
- versioning must be enabled on both the source and destination buckets
- files in an existing bucket are not replicated automatically
- delete markers are not replicated, deleting individual versions or delete markers will not be deleted
CloudFront Link to heading
key terms
- edge location: where the content will be cached
- origin: origin of all the files that CDN will distribute (can be S3, EC2, Elastic load balancer or route53)
- distribution: basically it’s a collection of edge locations. 1. web distribution 2. RTMP used for media streaming
note that
- edge location can not only read but also write(transfer acceleration)
- objects are cached for the life fo the TTL
- cache can be clear, but amazon will charge
CloudFront Signed URL or signed cookies Link to heading
CloudFront signed URL and signed cookie can be used under user cases like premium streaming stuff.
typically if you allow client to view one file, then use a signed URL; if you want him to view multiple files, then use signed cookies.
When we created a signed URL or signed cookie, we attach policies including URL expiration, IP ranges and trust signers.
From CloudFront to S3, use Origin Access Identity (OAI) to do a restricted access.
snowball Link to heading
snowball is the service amazon import/export large amount data to S3
once I heard amazon compares how sufficient transfer large amount data thru transportation over HTTP
storage gateway Link to heading
- file gateway: for files, stored directly on S3
- stored volumes: entire dataset is stored on site and is asynchronously backed up to S3
- cache volumes: entire dataset is stored on S3 and most frequently accessed data is cached on site
- gateway virtual tape library
athena Link to heading
- athena is an interactive query service
- it allows you to query data located in S3 using standard SQL
- serverless
- commonly used to analyse log data stored in S3
macie Link to heading
- macie uses AI to analyze data in S3 and helps identify PII (personal identifiable information)
- can also be used to analyse
CloudTraillogs for suspicious API activity - includes dashboards, reports and alerting
- great for PCI-DSS compliance and preventing ID theft
EC2 Link to heading
elastic compute cloud
pricing type: on demand, reserved, spot and dedicated hosts
if the spot instance is terminated by EC2, you will not be charged partial hour of usage; however if you terminate the instance youself, you will be charged for any hour.
- termination protection is turned off by default
- default action is for the root EBS volume to be deleted when the instance is terminated
- EBS root volumes can be encrypted
- additional volumes can be encrypted
spot instances and spot fleet Link to heading
spot instances can be used in stateless, fault-tolerant or flexible application scenarios, such as big data, containerized workload, CI/CD, high performance computing.
spot instances can request one time or persistent. When required persistent, it will start the instance and stop once its price go over your bid; and resume once its price go below your bid.
spot fleet is a collection of spot instances and, optionally, on-demand instances.
For spot fleet you can have capacityOptimized, lowestPrice, diversified and instancePoolToUseCount. lowestPrice strategy is the default one, the instances comes from the pool with lowest price; capacityOptimized will try to keep the capacity you set.
EC2 hibernate Link to heading
EC2 hibernate will save your RAM to EBS and stop the instance. And once restart it will resume the RAM and the RAM is so preserved. It’s much faster to boost up because you don’t need to reload your operating system. RAM has to be less than 150GB, won’t be hibernated for 60 days. Available for on-demand and reserved instances.
security group Link to heading
- all inbound traffic is blocked by default
- all outbound traffic is allowed
- changes to security groups take effect immediately
- can have multiple EC2 instances attached to multiple security groups
- security groups are stateful (if creating an inbound rule allowing traffic in, that traffic is allowed back)
- cannot block specific IP addresses using security groups, instead using network access control list
- can specify allow rules, but not deny rules
Elastic Block Store (EBS) Link to heading
| Solid State Drives (SSD) | Hard Disk Drives (HDD) | |||
|---|---|---|---|---|
| Volume Type | EBS Provisioned IOPS SSD (io1) | EBS General Purpose SSD (gp2)* | Throughput Optimized HDD (st1) | Cold HDD (sc1) |
| Short Description | Highest performance SSD volume designed for latency-sensitive transactional workloads | General Purpose SSD volume that balances price performance for a wide variety of transactional workloads | Low cost HDD volume designed for frequently accessed, throughput intensive workloads | Lowest cost HDD volume designed for less frequently accessed workloads |
| Use Cases | I/O-intensive NoSQL and relational databases | Boot volumes, low-latency interactive apps, dev & test | Big data, data warehouses, log processing | Colder data requiring fewer scans per day |
| API Name | io1 | gp2 | st1 | sc1 |
| Volume Size | 4 GB - 16 TB | 1 GB - 16 TB | 500 GB - 16 TB | 500 GB - 16 TB |
| Max IOPS**/Volume | 64,000 | 16,000 | 500 | 250 |
| Max Throughput***/Volume | 1,000 MB/s | 250 MB/s | 500 MB/s | 250 MB/s |
| Max IOPS/Instance | 80,000 | 80,000 | 80,000 | 80,000 |
| Max Throughput/Instance | 2,375 MB/s | 2,375 MB/s | 2,375 MB/s | 2,375 MB/s |
| Price | $0.125/GB-month$0.065/provisioned IOPS | $0.10/GB-month | $0.045/GB-month | $0.025/GB-month |
| Dominant Performance Attribute | IOPS | IOPS | MB/s | MB/s |
click here for more
volumes, snapshots and AMI Link to heading
- volumes exist on EBS. EBS –> virtual hard disk
- snapshots exist on S3. snapshots –> a photograph of the disk
- snapshots are point in time copies of volumes.
- snapshots are incremental – this means that only the blocks that have changed since your last snapshot are moved to S3
- taking snapshot can be done at both when instance is running or stopped. However, it’s best practice to take snapshot when the instance is stopped.
- you can create AMI from snapshots
- you can change EBS volume type and size on the fly
- volumes will always be in the same availability zone as the EC2 instance.
tricks to move EC2 from one availability zone to another
take snapshot of the EC2 –> create AMI from the snapshot –> use the AMI to launch the EC2 instance in a new availability zone.
tricks to move EC2 from one region to another
take snapshot of the EC2 –> create AMI from the snapshot –> copy the AMI from on region to another –> use the copied AMI to launch the new EC2 instance in the new region.
instance storage vs EBS Link to heading
instance storage is also called ephemeral storage
- instance storage cannot be stopped. if the host fails, you will lose data
- EBS backed instances can be stopped.
- you can reboot both, you will not lose your data
- both root volumes will be deleted on termination by default. with EBS volume, you could tell AWS to keep the root device volume
- EBS replicated data within the same AZ by default; S3 replicate data to multi AZs by default.
ENI vs EN vs EFA Link to heading
Elastic Network Interface (ENI)
it’s essentially a virtual network card. it would be used for basic networking. scenarios including needs of a seperate management network to your production network or a seperate logging network and doing in a low cost.
Enhanced Network
used for enhancing network throughput (reliable and high throughput), a user case scenario would be HPC networking requirements.
Enhanced Network Adapter
It supports up to 100Gbps for supported instances.
Elastic Fabric Adaptor
EFA is used when needs to accelerate high performance computing (HPC) and machine learning applications or need to do an OS by-pass.
encryption and snapshots Link to heading
- you can only share unencrypted snapshots
- snapshots can be shared with other AWS account or make it public
good old days when you cannot encrypted root device when creating it Link to heading
how to encrypt the root device then
- create a snapshot of the unencrypted root device volume
- create a copy of the snapshot and select the encrypt option
- create an AMI from the encrypted snapshot
- use the AMI to launch new encrypted instances
CloudWatch vs CloudTrail Link to heading
- CloudWatch is used for monitoring performance however CloudTrail is use for auditing (API calls to AWS, user management)
- CloudWatch can monitor most of AWS as well as your applications that run on AWS
Elastic File System (EFS) Link to heading
EFS can be share among several EC2 instances
- supports NFSv4 protocal
- only pay for the storage you use
- can scale up to petabytes
- support thousands of concurrent NFS connections
- data is stored across multiple AZ’s within a region
- read after write consistency
EFS vs FSX for Windows vs FSX for Lustre Link to heading
- EFS: when need distributed, highly resilient storage for linux instances and linux based applications
- FSX for Windows: when need centralized storage for Windows-based applications such as SQL server or any other native MS application
- FSX for Lustre: when need high-speed, high capacity distributed storage. this will be for HPC, financial modeling, etc. FSX for Lustre can store data directly on S3.
EC2 placement groups Link to heading
there are three kinds of groups
clustered placement group
clustered placement group are recommended for applications need low network latency and high throughput
spread placement group
spread placement groups are for applications that have a small number of critical instances that should be kept from each other
Amazon commits that instances within spread placement groups will be on different racks
partitioned
Amazon divides each group into logical segments. EC2 ensures that each partition within a placement group has its own rack, each rack has its own network and power source. allow you to isolate the impact of hardware failure within your application.
for multiple EC2 instances could be HDFS, HBase and Casssandra.
- a clustered placement group cannot span multiple availibility zones, however spread placement and partitioned group can.
- name you specify for a placement group must be unique within your AWS account.
- cannot merge placement groups.
- you can move an existing instance into placement group. but before move, the instance must be stopped and you can only move via CLI and SDK.
AWS and HPC Link to heading
We can achieve HPC on AWS by
data transfer
compute and networking
storage
orchestration and automation
data transfer
By using Snowball, SnowMobile which will transfer terabytes and perabytes of data. Or using DataSync sync data to store on S3, EFS, FSx for Windows, etc. Or Direct Connect.
- compute and networking
Options are EC2 instances be GPU and CPU optimized, EC2 fleets (spot instances and spot fleets), placement groups specifically cluster placement groups, Enhanced networking single I/O Virtualization (SR-IOV), Enhanced Network Adapter and Enhanced Fabric Adapter.
- storage
Instance-attached storage including EBS 64000 IOPS or provisioned IOPS or Instance Store which has low latency. Network storage including S3, EFS and FSx for Lustre
- orchestration and automation
AWS Batch and AWS ParallelCluster
Web Application Firewall (WAF) Link to heading
layer 7 application
when asked to block malicious IP addresses, malicious script, blocking requests certain country originated from
you can use either WAF or network ACLs (will be discussed in VPC)
when you are asked to block an IP, use NACL.
EC2 miscellenous Link to heading
- use
curl http://169.254.169.254/latest/meta-data/to see various meta data for this EC2 - I cannot move a reserved instance form one region to another, however depending on type of RI I can modify AZ, scope, network platform, instance size etc.
- EBS, EFS and FSx are all block-based storage
- If EBS is additional partition, I can detach it without stopping the instance
- I can change a role even if it was assigned and will take effect immediately
- you can attach Provisioned IOPS (io1) EBS volumes to multiple EC2 instances (new as Feb 2020)
Databases in AWS Link to heading
6 relational DB on AWS are SQL Server, Oracle, MySQL, PostgreSQL, Aurora and MariaDB
relational DBs has two features on AWS:
- multi AZ - for disaster recovery
- read replicas - for performance
read replicas will have to setup connections by user manually.
DynamoDb is Amazon’s no sql solution
OLTP vs OLAP
OLAP requires data warehouse solution, Amazon’s data warehouse solution is called Redshift
Redshift is used for business intelligence
relational DB on AWS Link to heading
- RDS runs on virtual machines, however you as a user cannot access to that virtual machine. Patching of the RDS OS and DB is Amazon’s responsibility.
- RDS is NOT serverless
- Aurora serverless is serverless
backups, multiAZ and read replicas Link to heading
- backups
two different types of backups
- automated backups
- database snapshots
DB snapshots are done manually and they are stored even after you delete the original RDS instance.
Business always define Recovery Point Objective and Recovery Time Objective, usually RPO is in minutes and RTO is in hours.
RPO refers to maximum period of data loss that is acceptable in the event of a failure or incident. RTO refers to maximum amount of downtime that is permitted to recover from backup and to resume processing
- multiAZ
multiAZ allows you to have copy of your production db, amazon handles the replication for you so it will auto failover to standby db when needed.
multiAZ is used for disaster recovery.
you can force a failover from one AZ to another by rebooting the RDS instance.
- read replicas
read replicas is used for performance improvements.
* used for scaling
* must have automatic backups turned on in order to deploy a read replica.
* you can have up to 5 read replicas of any db.
* you can have read replicas of read replicas( watch the latency)
* each read replica will have its own DNS endpoint.
* you can have read replicas that have multiAZ
* you can create read replicas of multiAZ source db
* read replicas can be promoted to their own db, but it will break the replication
* can have a read replica in a second region
dynamoDB Link to heading
amazon’s no sql service
- stored on SSD so that it’s quick
- spread across 3 distinct data center
- eventual consistent reads (default)
- strongly consistent reads
redshift Link to heading
backups for redshift
- only available in 1 AZ
- enable by default with 1 day retention period up to 35 days
- it always attempts to maintain at least 3 copies of your data (the original and replica on the compute nodes and a backup in Amazon S3)
- redshift can also asynchronously replicate your snapshots to S3 in another region for disaster recovery
Amazon Redshift organizes the data by column instead of storing data as a series of rows. Because only the columns involved in the queries are processed and columnar data is stored sequentially on the storage media, column-based systems require far fewer I/Os, which greatly improves query performance.
aurora Link to heading
- 2 copies of your data are contained in each AZ with minimum of 3 AZ. in total 6 copies in min
- it will handle the loss of up to 2 copies of data w/o affecting write, 3 copies of data w/o affecting read
- can share aurora snapshots with other AWS accounts
- only 3 types of replicas available in aurora, they are aurora replicas (up to 15), MySQL replicas (up to 5) and PostgresQL replicas (up to 1), only aurora replica does failovers
- use aurora serverless if you want a simple, cost-effective option for infrequent, intermittent or unpredictable workloads.
Elasticache Link to heading
in-memory cache in the cloud
- memcached
- redis
redis can be multi AZ redis can do backup and restore
Database Migration Service (DMS) Link to heading
As the name indicated, DMS will migrate data from one database to another, what interesting is AWS DMS will do on-promises to on-promises, on-promises to cloud, cloud to on-promises or cloud to cloud. It can as do homogeneous migration or heterogeneous migration.
However when doing a heterogeneous migration it will need a schema-convertion-tool.
for example, data from Oracle to Aurora, you will need schema conversion sometimes.
Cache Strategy Link to heading
Caching is the balance act between up-to-date, accuracy and latency. The following services can cache
- CloudFront
- API Gateway
- ElasticCache
- DynamoDB Accelerator (DAX)
The lower the services the more latency it gets.
Elastic Map Reduce Link to heading
Amazon EMR is industry leading cloud big data platform process data using open source tools such as apache series.
Central component of Amazon EMR is the cluster. A cluster is a collection of EC2 instances. Each instance in the cluster called a node. Each node has a role within the cluster as node type.
Node types can be master node, core node, task node.
The master node tracks the status of the tasks and monitor the health of the cluster.
The core node runs the task and store the data.
The task node only runs tasks, doesn’t store data in HDFS.
Only when created the cluster, you can configure master node archive the log files to S3, you cannot change it after you created the cluster.
IAM Advanced Link to heading
What is Active Directory (AD) Link to heading
AD comes from Windows. It’s on-promises directory service with hierarchical database of users, groups computers with tree and forest structure. There are group policies. It uses LDAP and DNS protocol. It uses Kerberos, LDAP and NTLM as authentication. It can be highly available.
What is AWS Active Directory Service for Microsoft active directory Link to heading
It’s a managed active directory service hosted on cloud. It’s best to be used when 5000 and more people using AD Trust between AWS and on-promises AD.
AWS managed AD has AD domain controllers. DCs also managed by AWS (they are windows servers).
AWS managed AD is reachable by your applications in your VPC, with DCs adding, it’s HA and of high performance.
Simple AD Link to heading
As the name indicated, it’s simpler than AWS manged AD.
It’s a standalone managed directory with basic AD features. Small is less than 500 people and large is less than 5000 people. It’s easier to manage EC2s. Linux workloads need LDAP.
Because it’s supporting basic features, so it’s not supporting AD Trust, so you cannot join on-promises AD to Simple AD.
AD connector Link to heading
AD connector is like a proxy (Directory Gateway) for on-promises AD. It allows on-promises users to login to AWS so that it avoid cacheing information on cloud.
You can join EC2s to your existing AD domain, and scale across multiple AD connectors.
Cloud Directory Link to heading
Cloud Directory is a directory-store based store for developers. It contains hierarchies with hundreds of millions of objects. It’s an AWS fully managed service, you can find org charts, registar, etc.
Amazon cognito user pools Link to heading
It’s a managed user directory for Saas applications. It’s been used for sign-up and sign-in to web and mobile. Worked with social media identities.
Exam tips Link to heading
- AD compatible services: AWS managed AD, Simple AD and AD Connector
- AD incompatible services: Cloud Directory, AWS Cognito User Pool.
Route53 Link to heading
DNS 101 Link to heading
cloudflare links here.
A record
The ‘A’ stands for ‘address’ and this is the most fundamental type of DNS record, it indicates the IP address of a given domain.
‘A’ records only hold Ipv4 addresses, if the site has a Ipv6 address, it will instead use an ‘AAAA’ record.
example.com record type: value: TTL @ A 12.34.56.78 14400 Name Server records
The NS record indicates which DNS server is authoritative.
Example of an NS record:
example.com record type: value: TTL @ NS ns1.exampleserver.com 21600 Canonical Name record (CNAME record)
The ‘canonical name’ record is used in lieu of an A record, when a domain or subdomain is an alias of another domain.
All CNAME records must point to a domain, never to an IP address.
blog.example.com record type: value: TTL @ CNAME is an alias of example.com 32600 Start Of Authority (SOA record)
The ‘start of authority’ record can store important info about the domain such as the email address of the administrator, when the domain was last updated, and how long the server should wait between refreshes.
example.com record type: value: TTL @ SOA admin.example.com 11200 Pointer Record (PTR Record)
A pointer (PTR) record is a type of Domain Name System (DNS) record that resolves an IP address to a domain or host name. PTR records are used for the reverse DNS lookup. Using the IP address, you can get the associated domain or host name.
Sender Policy Framework Record (SPF Record)
An SPF record is a Sender Policy Framework record. It’s used to indicate to mail exchanges which hosts are authorized to send mail for a domain.
Route53 specific Link to heading
ELBs don’t have pre-defined ipv4 addresses, you resolve to them using a DNS name.
Alias records
Alias records are used ot map resource record sets in your hosted zone to Elastic Load Balancers, CloudFront distributions or S3 buckets that are configured as websites.
Alias records work like a CNAME record in that you can map one DNS name to another ’target’ DNS name.
the key difference between CNAME and Alias Record is that CNAME cannot be used for zone apex record (eg. you cannot have yourdomain.com as a CNAME)
CNAME hack in cloudflare
CloudFlare now supports CNAME Flattening, which is a better solution to this same problem. in other words, CloudFlare allows you to set your zone apex to a CNAME.
so basically you can do this now using cloudflare
yourdomain.com CNAME some-id.ec2.amazonaws.com
Simple Routing Policy Link to heading
Using A Recored. if you have one record with multiple IP addresses, route 53 will return values in random order.
Weighted Routing Policy Link to heading
Using A Record. as name indicated it goes to different IP addresses using weigh that you set.
latency based routing policy Link to heading
Using A Record. latency routing will give user the lowest response time.
failover routing policy Link to heading
active/passive pattern. once the health check is not passed, it will failover to passive IP address.
geolocation routing policy Link to heading
send user based on user’s location
geoproximity routing policy Link to heading
to use geoproximity routing you must enable traffic flow
multivalue answers routing policy Link to heading
similar to simple, but can associate health check to it.
Virtual Private Cloud (VPC) Link to heading
think of VPC consists of IGW(or virtual private gateways), route tables, network Access Control Lists, Subnets, and security groups
1 subnet = 1 AZ subnet cannot span availability zones
security groups are stateful whereas ACLs are stateless
and VPCs doesn’t allow TRANSITIVE PEERING
VPC peering Link to heading
- allows to connect one VPC with another via a direct network route using private IP addresses
- instances behaves as if they were on the same private network
- can peer VPC with other AWS accounts as well as with other VPC in the same account
- peering is in a star configuration: ie 1 central VPC peers with 4 others
- peering can among regions
VPC creation (have to remember) Link to heading
when freshly created, vpc comes with a default route table, network access control list and a default security group
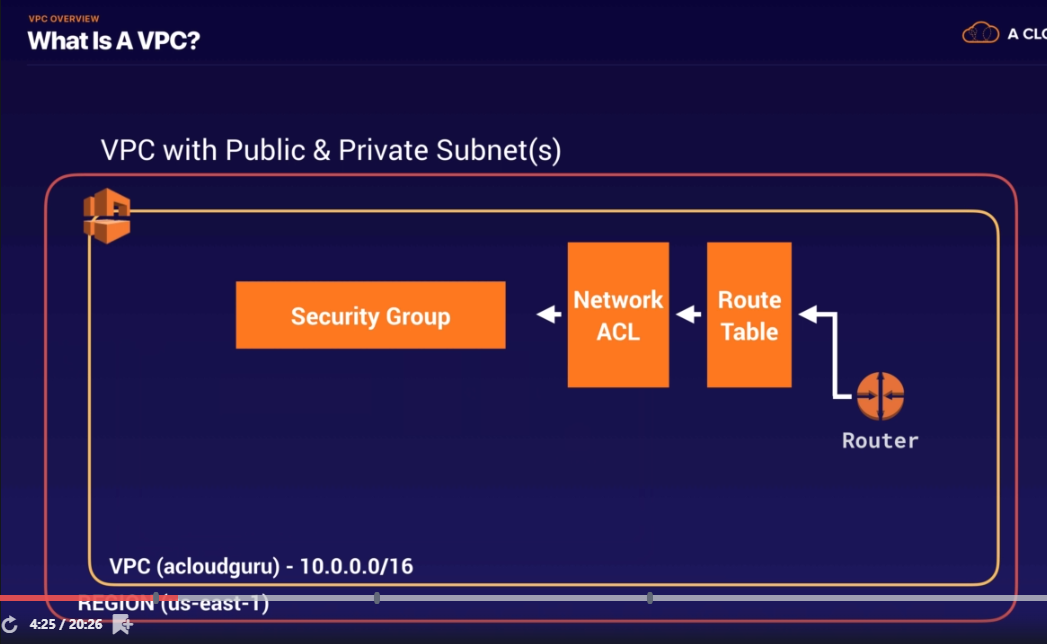
it won’t create any subnets nor will it create a default internet gateway
the next step would be create a internet gateway, and associate to the VPC just created. in order to let internet traffic flow in, have to configure the route table, ACL and security group stuff if necessary.
the next step would create subnets
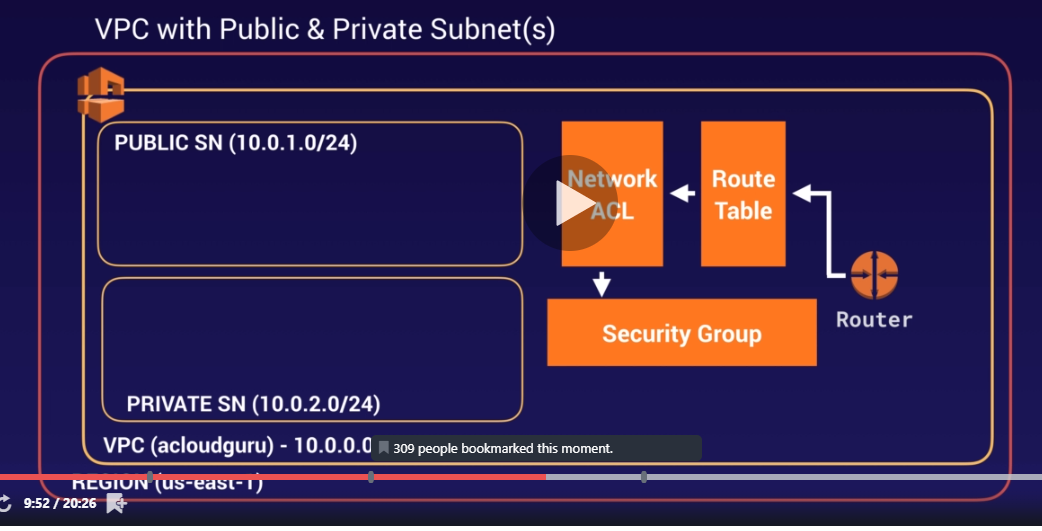
and then create route tables, leave the default route table as is, and create another route table to deal with public subnets
after the creation, select the route table just created and associate public subnet with it
also don’t forget to add routes into it
next step, create instances in each subnet
select subnet accordingly, will find auto-assign public ip being “use subnet setting (enable)” or disable depending on which subnet you are choosing.
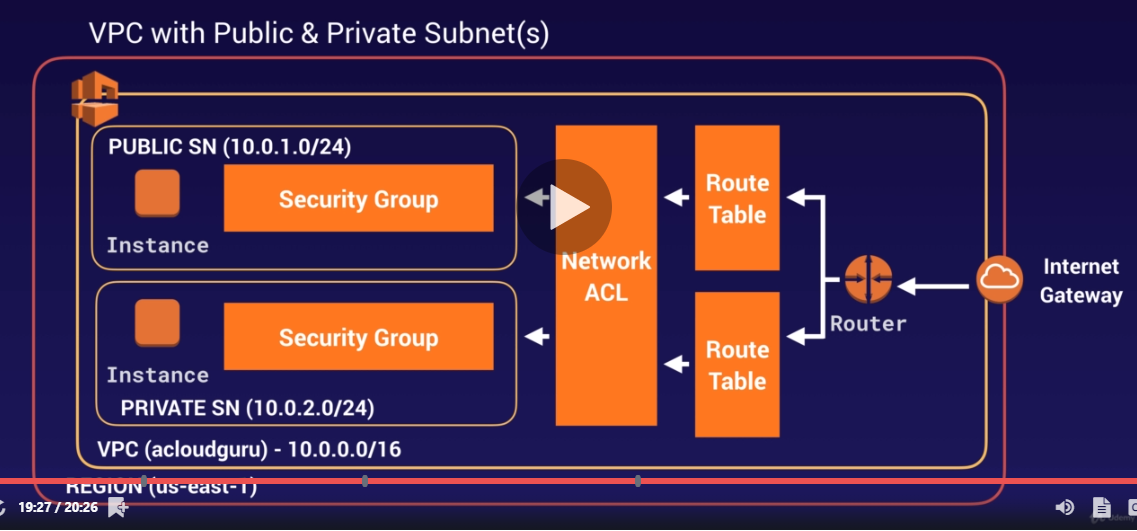
now we want instance in public subnet talks to instance in private subnet, what we do is to create a security group
within configuring SG, use cidr to config the inbound rule and outbound rule. then public and private instance could talk to each other.
VPC charateristics Link to heading
- the same AZ name in one’s account (ie us-east-1a) can be completely different AZ in another account
- amazon reserve 5 IP addresses within your subnets
- you can only have 1 Internet Gateway per VPC (amazon guarantees highly availibility of that gateway)
- security group cannot span VPCs.
NAT instances and NAT gateways Link to heading
- when create a NAT instance, must disable source/destination check on the instance
- NAT instance must be in a public subnet
- must modify route table of private subnet to the NAT instance in order for this to work
- NAT instance is behind a security group
whereas NAT gateway is
- redundant inside the AZ
- not associate with the security group
- automatically assigned with a public ip address
- remember to update your route tables
- no need to disable source/destination checks
both NAT instance and NAT gateway needs to update route table and better create NAT gateways in each AZ to have a AZ-independent architecture
Network ACLs vs Security groups Link to heading
The difference between Security Group and ACLs is that, Security Group act as a firewall for associated Amazon EC2 instances, controlling both inbound and outbound traffic at the instance level, while ACLs act as a firewall for associated subnets, controlling both inbound and outbound traffic at the subnet level.
- you can associate a network ACL with multiple subnets, however a subnet can be associated with only one network ACL at a time.
- network ACLs contain a numbered list of rules that evaluated in order, lowest numbered rule will overwrite higher number rule, whereas security group will access all the rules before it actually execute it.
- network ACLs are stateless; responses to allowed inbound traffic are subject to the rules for outbound traffic; in other word, you have to specify both inbound and outbound rules.
VPC flow logs Link to heading
- you cannot enable flow logs for VPCs that are peered with your VPC unless that VPC is in your account
- cannot tag flow logs
- after you’ve created a flow log, you cannot change its configuration; for example you cannot change its IAM role
not all traffic are monitored
- traffic generated by instances when they contact the Amazon DNS server.
- traffic generated by a Windows instance for Amazon Windows license activation
- traffic to and from 169.254.169.254 for instance metadata
- DHCP traffic
- traffic to reserved ip address for the default VPC router.
Bastions Link to heading
what is a bastions
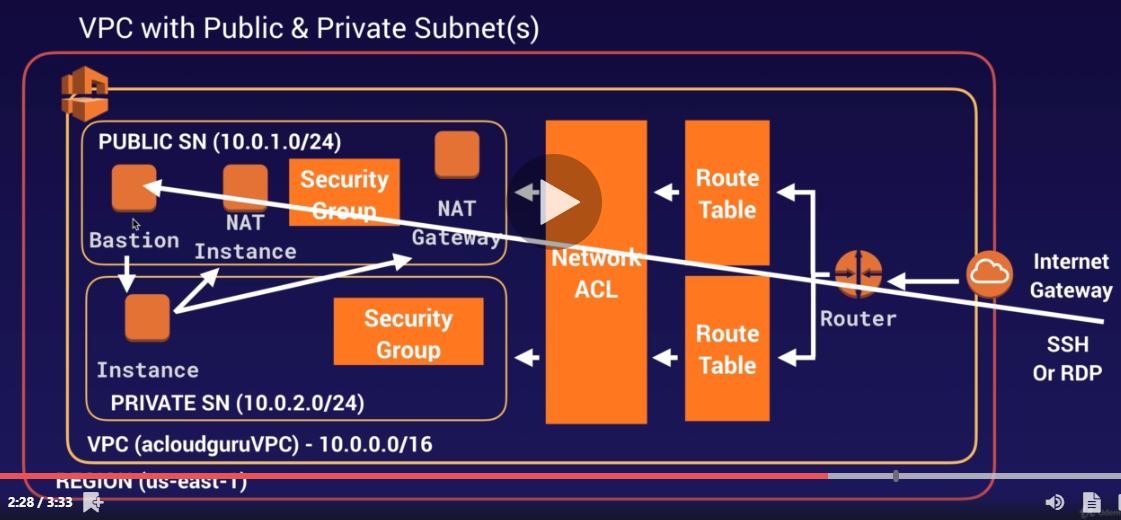
To reduce exposure of servers within the VPC you will create and use a bastion host
cannot use NAT gateway as a bastion host
Direct Connect Link to heading
it directly connects your data center to AWS as the name indicated. useful for high throughput and needs for stable and realiable secure connection.
Steps to set up direct connections
- create a virtual interface in the Direct Connect Console. This is a Public Virtual Interface.
- go to VPC console and then to VPN connections, create a Customer Gateway.
- create a virtual private gateway
- attach the virtual private gateway to the desired VPC
- select VPN connections and create new VPN connections and select the virtual private gateway and the customer gateway
- once the VPN is available, setup the VPN on the customer gateway or firewall
Global Accelerator Link to heading
reference from amazon
global accelerator is to improve availability and performance of your application for local and global
some components in AWS global accelerators
- static ip addresses
- accelerator itself
- DNS name
- network zone
- listener
- endpoints group
- endpoint
amazon provides 2 ip addresses. And Amazon assigns each accelerator a default DNS name that points to the static ip address.
And when you configure accelerator, by default global accelerator allocates 2 ipv4 addresses for it. (seems like each ipv4 address is in a network zone). A network zone services the static ip addresses for you accelerator from a unique ip subnet, it is an isolated unit with its own infrastructure like AZ.
a listener processes inbound connections from clients to global accelerator. support both TCP and UDP. each listener has one or more endpoint groups associated with it and traffic is forwared to endpoints in one of the groups.
endpoint groups include one or more endpoints in the region, there is a traffic dial option lets you easily do performance testing or blue/green deployment testing for new releases accross different AWS regions.
endpoint, however different from endpoint groups, can be network load balancers, application network load balancers, EC2 instances or Elastic ip addresses.
VPC endpoints Link to heading
VPC endpoint enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT, VPN or Direct Connection. traffic doesn’t leave amazon network.
There are two types of VPC endpoints: interface endpionts and gateway endpoints
gateway endpoints support: S3 and DynamoDB.
one scenario using VPC gateway endpoint would be replacing NAT instances or NAT gateways.
VPC Miscellaneous Link to heading
- are you permitted to do vulnerability scan without telling AWS? AWS just changed their policy about alerting, though there still are conditions.
- By default, instances in new subnets in a custom VPC can communicate with each other across Availability Zones.
- A Bastion host allows you to securely administer (via SSH or RDP) an EC2 instance located in a private subnet. Don’t confuse Bastions and NATs, which allow outside traffic to reach an instance in a private subnet.
- You would only allow 0.0.0.0/0 on port 80 or 443 to to connect to your public facing Web Servers, or preferably only to an ELB. Good security starts by limiting public access to only what the customer needs. Please see the AWS Security whitepaper for complete details.
High Availability architecture Link to heading
Load Balancers Link to heading
there are 3 types of load balancers
- application load balancer
This is dealing with http and https requests (dealing request level). layer 7 and application aware.
- network load balancer
This is dealing with tcp and udp (dealing connection level). layer 4. can handle millions rps
- classic load balancer
This is an old balancer, load balance at both request and connection level. But this load balancer doesn’t have a single connection with new application load balancer and network load balancer.
legacy elastic load balancers. produce 504 error code.
X-Forward-For header can passing client ip addresses.
Read ELB FAQ for classic load balancers.
Listeners Link to heading
Every load balancer must have one or more listeners configured. A listener is a process that checks for connection requests—for example, a CNAME configured to the A record name of the load balancer. Every listener is configured with a protocol and a port (client to load balancer) for a front-end connection and a protocol and a port for the back-end (load balancer to Amazon EC2 instance) connection – AWS certified solution architect official study guide
load balancer theory Link to heading
- sticky session enable your users to stick to the same EC2 instance. real world user case is storing information locally to that instance.
- cross zone load balancing enables you to load balance accross multiple availability zones.
- path patterns allow you to direct traffic to different EC2 instances based on the URL contained in the request.
autoscaling Link to heading
there are 5 scaling options
- maintain current instance levels at all times.
- scale manually.
- scale based on a schedule
- scale based on demand
- user predictive scaling
Application Link to heading
Simple Queue Service (SQS) Link to heading
a distributed queue system
SQS offers two types of queues
- standard queue
- FIFO queue
standard queue offered as a default type. the standard queue guarantees that a message is delievered at least once. standard queue has capability dealing with unlimited number of transactions per second.
standard queue provide best-effort ordering but it doesn’t gurantee the order.
whereas
FIFO queue process a message exactly once. FIFO queues are limited to 300 transactions per second.
SQS is pull-based NOT pushed-based.
messages are 256 kb in size, and can be kept in the queue from 1 minute to 14 days. the default retention period is 4 days.
visibility timeout is the amount of time that the message is invisible in the SQS queue after a reader picks up that message. provided the job is processed before visibility timeout expires, the message will then be deleted from the queue. if the job is not processed within that time, the message will become visible again and another reader will process it. this could result in the same message being delivered twice.
SQS visibility timeout default is 30 seconds, max visibility timeout is 12 hours.
SQS retention period default is 4 days, min 60 seconds, max 14 days.
SQS long polling is a way to optimize your cost. while the short polling returns immediately (even if the message queue is empty), long polling doesn’t return a response until a message arrives in the queue, or the long poll times out.
max long polling timeout is 20 seconds
Simple Work Flow (SWF) Link to heading
Amazon warehouse uses SWF
SWF is a web service that makes it esay to coordinate work accross distributed application components.
SQS has retention period of up to 14 days; with SWF, workflow executions can last up to 1 year.
SWF presents a task-oriented API
SWF ensures that a task is assigned only once and is never duplicated, whereas SQS, application might need to handle duplicated messages.
SWF has “actors”:
- workflow starters: an application that can initiate a workflow.
- deciders: control the flow of activity tasks in a workflow execution.
- activity workers: carry out the activity tasks.
Simple Notification Service Link to heading
- instaneous, push-based delivery
- simple APIs and easy integration with applications
- flexible message delivery over multiple transport protocols
What happens when you create a topic on Amazon SNS?
an amazon resource name is created
SNS vs. SQS Link to heading
- both are messaging services in AWS
- SNS is push-based
- SQS is poll based
Elastic Transcoder Link to heading
converting media files from original format to different formats.
API Gateway (5-10marks) Link to heading
API Gateway is at high level
- API Gateway has caching capabilities to increase performance
- API Gateway is low cost and scales automatically
- one can throttle API Gateway to prevent attacks
- enable CORS on API Gateway
- CORS is enforced by client(mostly browser in modern days)
Kinesis Link to heading
First understand what is streamning data. streaming data is generated continuously by thousands of data sources, send in the data records simultaneously and in small sizes (we are talking about kb)
Amazon kinesis is a platform on AWS to send your streaming data to
there are 3 kinds of kinesis
- kinesis streams
- kinesis firehose
- kinesis analytics
kinesis streams would persist data into shard 1 to 7 retention. the data could be consumed by ec2 instance. shards can do 5 transactions per second for reads with maximum total data read rate of 2MB shards can do 1000 records per second for writes, up to a maximum total data write rate of 1MB
data capacity of your stream is a function of the number of shards that you specify for the stream. the total capacity fo the stream is the sum of the capacities of its shards
kinesis firehose doesn’t persist data. it can use an optional lambda function
kinesis analytics can analyze data on the fly
Web Identity Federation and Amazon Cognito Link to heading
web identity federation allows users to authenticate with a web identity provider (google, facebook, amazon)
in order to go into details, we have to understand what is user pool and what is identity pool.
cognito user pool are user directories used to manage sign-up and sign-in functionality for mobile and web applications. cognito acts as a broker between identity provider like Facebook and AWS. successful authentication generates a JSON Web token.
cognito identity pool provide temporary AWS credentials/IAM rols
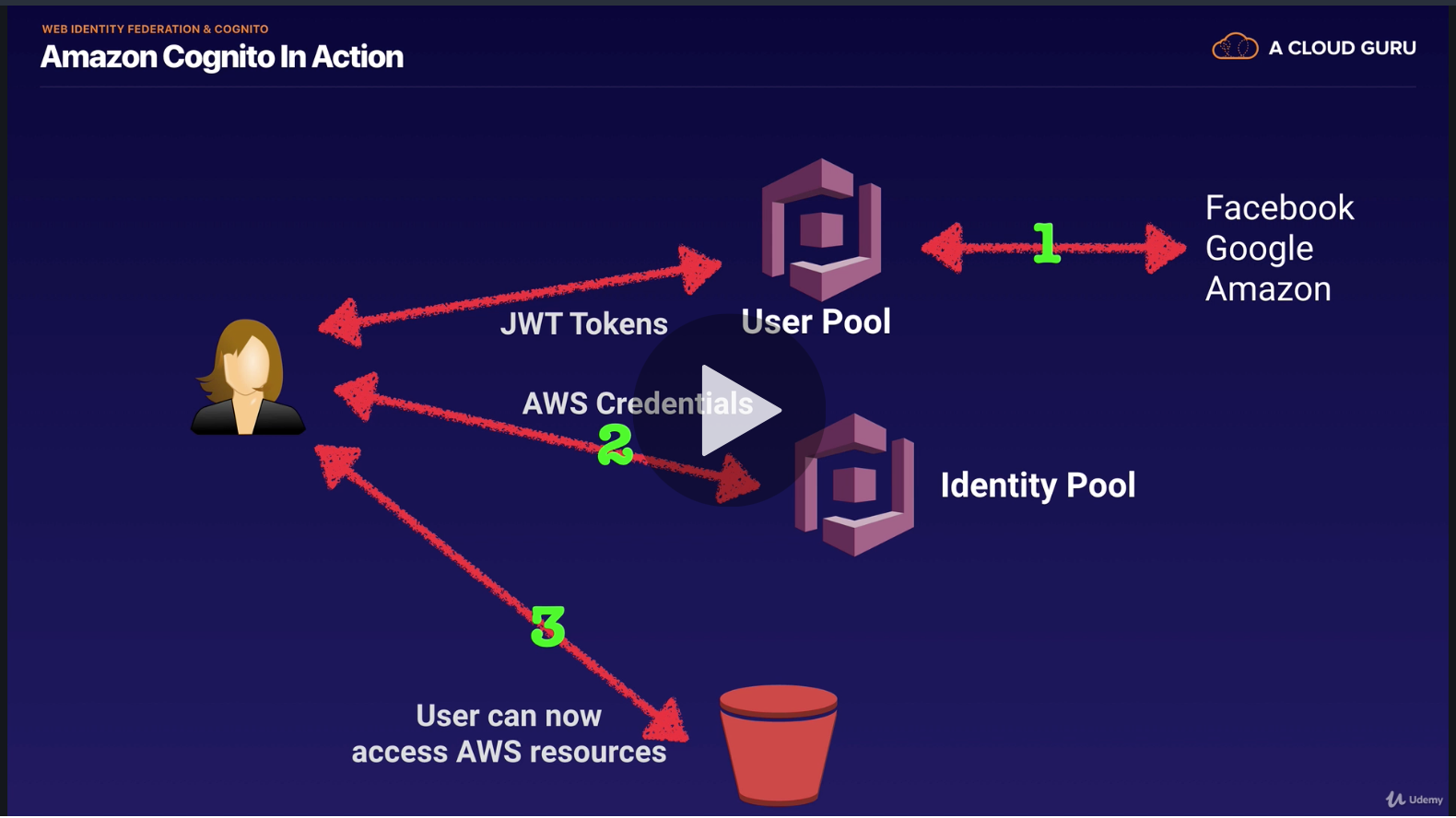
AWS cognito can push silent SNS notifications accross platforms to update the user data
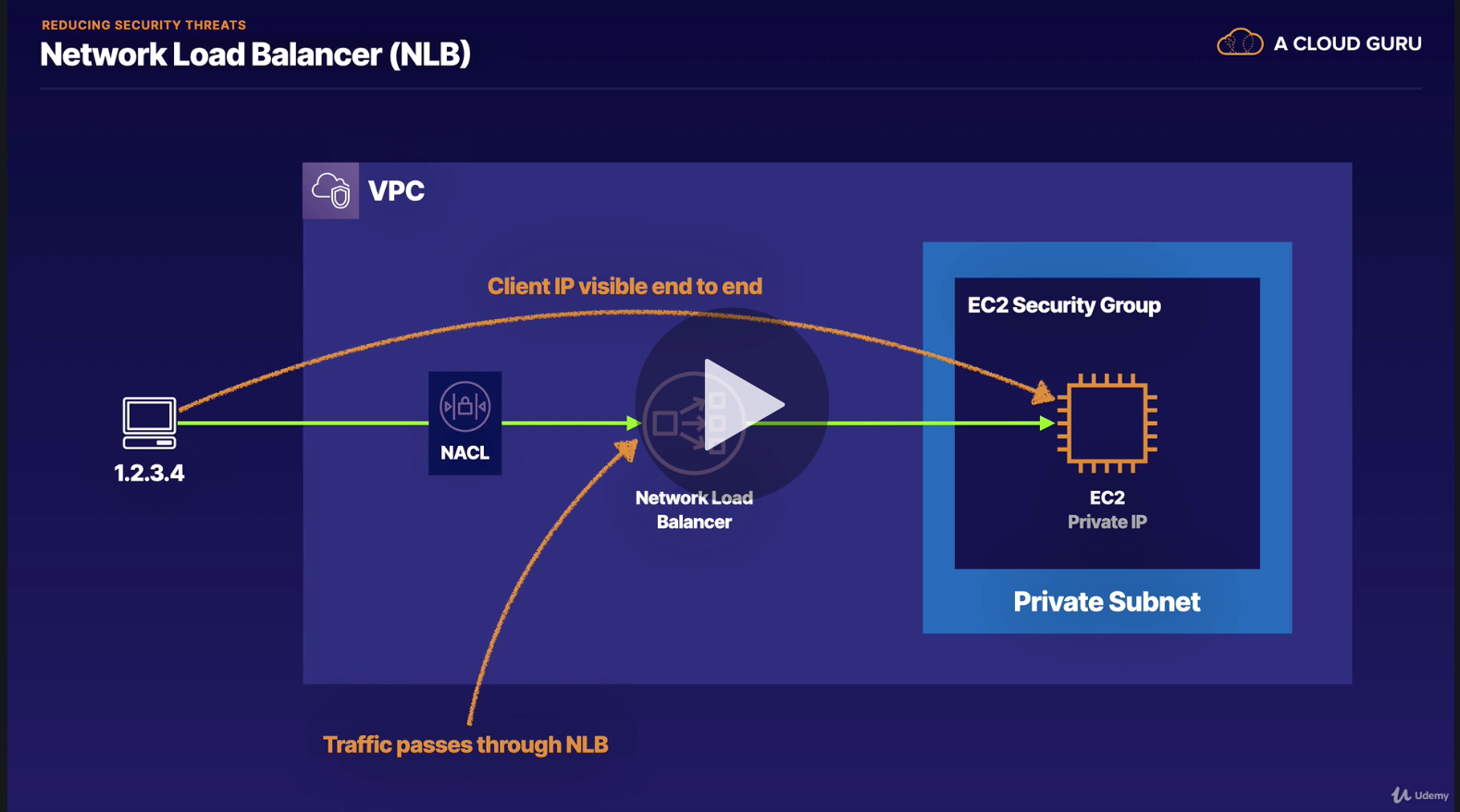
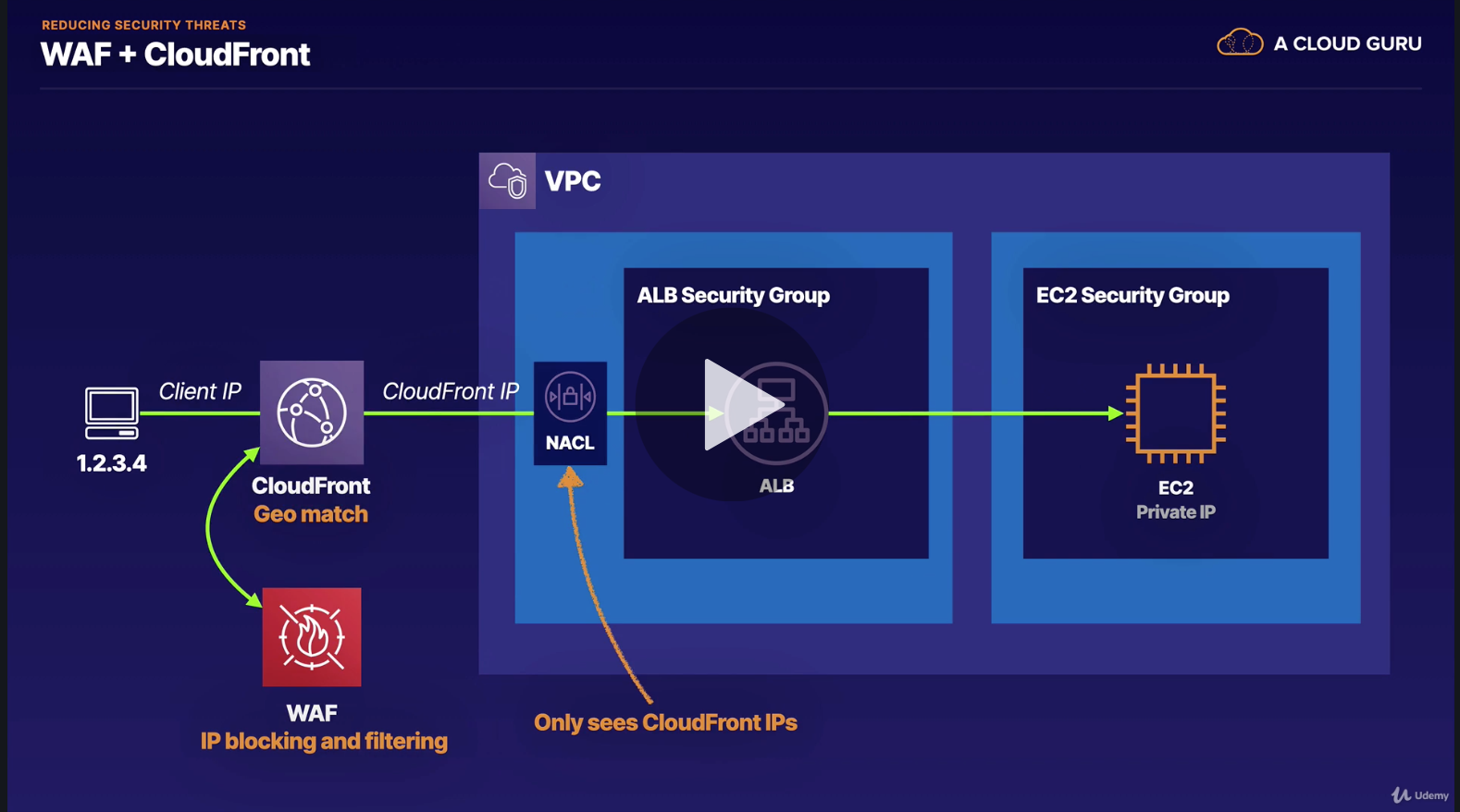
Security Link to heading
in order to reduce security threats, we could take several methods
- ALB Blocking
using ALB can block IPs at ALB, but EC2 security group will become pointless.

- NLB Blcoking
using NLB, NLB will pass ip on to EC2, so will rely on EC2 to block IPs.
- WAF + CloudFront Blocking
When using CloudFront, IP will become CloudFront’s IP, EC2 doesn’t know the real IP. So we need to setup a WAF in CloudFront to block IP.
KMS Link to heading
KMS will make it easier for you to manage keys for encrypting purposes.
CMK and Data Keys Link to heading
Customer Master Key are fundamental resources AWS KMS manages. CMK NEVER leaves KMS. Whereas CMK can encrypt data keys, and Data Keys CAN leave KMS.

Data Keys and Envelope Encryption Link to heading
AWS KMS uses envelope encryption to protect data. The reason it’s calling Envelope Encryption is because it uses more than one keys other than root key to protect data.
KMS creates a data key (plain text version). And CMK encrypts it under KMS (encrypted version). KMS will return plain text and encrypted versions of the data keys to you.
You will use plain text key to encrypt data. You will use encrypted key to retrieve plain text key.
how to decrypt text Link to heading
Your encrypted key and encrypted data will be stored together. When you want to decrypt, you have to provide the exact same encrypted data.
CloudHSM Link to heading
- What is CloudHSM and its features
CloudHSM is a dedicated hardware security module.

- What is the typical structure

Serverless Link to heading
Lambda Link to heading
- Lambda scales out (not up) automatically. scale out here meaning 1 call triggers 1 lambda, 2 calls trigger 2 lambdas
- Lambda functions are independent, 1 event = 1 function
- Lambda is serverless
- Arura, Lambda, S3, API gateway, etc are serverless
- Lambda functions can trigger other lambda functions, 1 event can = x functions depending the design
- AWS x-ray allows you to debug what is happening for serverless app.
- Lambda can do thing in AWS globally.
- events will trigger lambda, like upload to S3, SNS notifications, etc. know the triggers!
serverless vs traditional
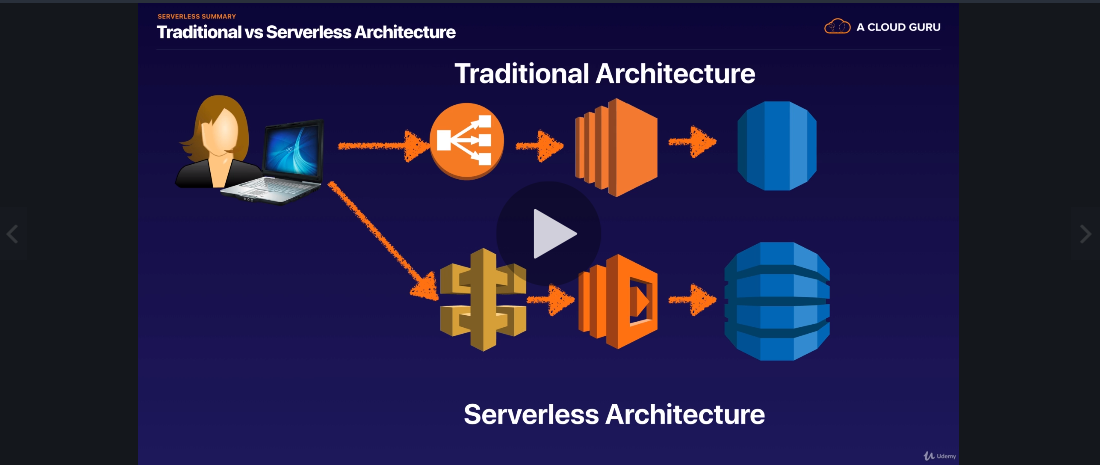
serverless miscellineous Link to heading
- Like any services in AWS, Lambda needs to have a role associated with it that provide credentials with rights to other services. This is exactly the same as needing a role on an EC2 instance to access S3 or DDB.
- The exact ratio of cores to memory has varied over time for Lambda instances, however Lambda like EC2 and ECS supports hyper-threading on one or more virtual CPUs (if your code supports hyper-threading).