Don’t feel afraid of ‘fancy’ syntax of Apache Beam Python
Basic Concepts Link to heading
pipelines Link to heading
A pipeline encapsulates the entire series of computations involved in reading input data, transforming that data, and writing output data. The input source and output sink can be the same or of different types, allowing you to convert data from one format to another. Apache Beam programs start by constructing a Pipeline object, and then using that object as the basis for creating the pipeline’s datasets. Each pipeline represents a single, repeatable job.
PCollection
Link to heading
A
PCollectionrepresents a potentially distributed, multi-element dataset that acts as the pipeline’s data. Apache Beam transforms usePCollectionobjects as inputs and outputs for each step in your pipeline. APCollectioncan hold a dataset of a fixed size or an unbounded dataset from a continuously updating data source.
PCollection has several characteristics:
PCollectionmust all be the same typePCollectionis immutablePCollectiondoesn’t support random access
Transforms Link to heading
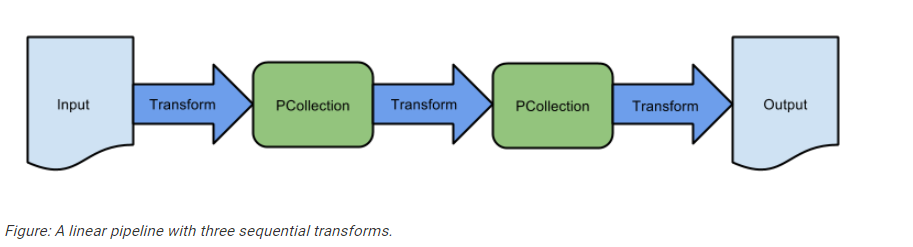
A transform represents a processing operation that transforms data. A transform takes one or more
PCollectionsas input, performs an operation that you specify on each element in that collection, and produces one or morePCollectionsas output. A transform can perform nearly any kind of processing operation, including performing mathematical computations on data, converting data from one format to another, grouping data together, reading and writing data, filtering data to output only the elements you want, or combining data elements into single values.
in python, Beam SDK has a generic apply method or simply use |.
core Beam Transforms are
ParDo~=
Map. parallel processing. when you apply aParDo, you need provide aDoFnObject.DoFnObject contains logic that applies to the elements in the input collection.When you use Beam, often the most important pieces of code you’ll write are these DoFns–they’re what define your pipeline’s exact data processing tasks. lightweighted
DoFns can be provided in line usinglambdafunctions.GroupByKeyGroupByKey represents a transform from a multimap (multiple keys to individual values) to a uni-map (unique keys to collections of values).
CoGroupByKeyCoGroupByKeyperforms a relational join of two or more key/valuePCollectionsthat have the same key typeCombineOnce using
Combine, one has to provideCombineFncontaining the combine logic.FlattenFlattenmerges multiplePCollectionobjects into a single logicalPCollection.PartitionPartitionis a Beam transform forPCollectionobjects that store the same data type.Partitionsplits a singlePCollectioninto a fixed number of smaller collections.
Windowing Link to heading
Windowing subdivides a PCollection according to the timestamps of its individual elements
Beam provides several windowing functions, including:
- Fixed Time Windows
- Sliding Time Windows
- Per-Session Windows
- Single Global Window
- Calendar-based Windows (not supported by the Beam SDK for Python)